本文由Gemini生成翻译后逐字校对修正
作者:Arian Maleki and Tom Do 斯坦福大学
概率论是对不确定性的研究。在本课程中,我们将运用概率论的基本概念来推导和理解机器学习算法。这份笔记旨在以适用于 CS229 课程的深度,介绍概率论的核心基础。概率的数学理论非常复杂,并深入到被称为测度论的分析分支。在本笔记中,我们将只对其基础进行阐述,不深入探讨其背后的复杂细节。
1. 概率的基本要素#
为了严谨地在一个集合上定义概率,我们需要以下几个基本要素:
样本空间 (Sample Space) Ω \Omega Ω :一个随机实验所有可能结果的集合。其中每一个结果 ω ∈ Ω \omega \in \Omega ω ∈ Ω
事件集 (Event Space) F \mathcal{F} F :由样本空间 Ω \Omega Ω F \mathcal{F} F A A A 事件 (Event),它代表了实验的一种或多种可能的结果集合 (A ⊆ Ω A \subseteq \Omega A ⊆ Ω
概率测度 (Probability Measure) :一个从事件集 F \mathcal{F} F R \mathbb{R} R P P P
P ( A ) ≥ 0 P(A) \ge 0 P ( A ) ≥ 0 A ∈ F A \in \mathcal{F} A ∈ F P ( Ω ) = 1 P(\Omega) = 1 P ( Ω ) = 1 如果 A 1 , A 2 , … A_1, A_2, \ldots A 1 , A 2 , … i ≠ j i \ne j i = j A i ∩ A j = ∅ A_i \cap A_j = \emptyset A i ∩ A j = ∅ P ( ∪ i A i ) = ∑ i P ( A i ) P(\cup_i A_i) = \sum_i P(A_i) P ( ∪ i A i ) = ∑ i P ( A i )
以上三条性质被称为概率公理 (Axioms of Probability) 。
示例 :考虑投掷一枚六面骰子的实验。其样本空间为 Ω = { 1 , 2 , 3 , 4 , 5 , 6 } \Omega = \{1, 2, 3, 4, 5, 6\} Ω = { 1 , 2 , 3 , 4 , 5 , 6 } F = { ∅ , Ω } \mathcal{F} = \{\emptyset, \Omega\} F = { ∅ , Ω } Ω \Omega Ω P ( ∅ ) = 0 , P ( Ω ) = 1 P(\emptyset) = 0, P(\Omega) = 1 P ( ∅ ) = 0 , P ( Ω ) = 1 P ( { 1 , 2 , 3 , 4 } ) = 4 6 P(\{1,2,3,4\}) = \frac{4}{6} P ({ 1 , 2 , 3 , 4 }) = 6 4 P ( { 1 , 2 , 3 } ) = 3 6 P(\{1,2,3\}) = \frac{3}{6} P ({ 1 , 2 , 3 }) = 6 3
基本性质 :
如果 A ⊆ B A \subseteq B A ⊆ B P ( A ) ≤ P ( B ) P(A) \le P(B) P ( A ) ≤ P ( B )
P ( A ∩ B ) ≤ min ( P ( A ) , P ( B ) ) P(A \cap B) \le \min(P(A), P(B)) P ( A ∩ B ) ≤ min ( P ( A ) , P ( B )) (联合界) P ( A ∪ B ) ≤ P ( A ) + P ( B ) P(A \cup B) \le P(A) + P(B) P ( A ∪ B ) ≤ P ( A ) + P ( B )
P ( Ω ∖ A ) = 1 − P ( A ) P(\Omega \setminus A) = 1 - P(A) P ( Ω ∖ A ) = 1 − P ( A ) (全概率定律) 如果 A 1 , … , A k A_1, \ldots, A_k A 1 , … , A k Ω \Omega Ω ∪ i = 1 k A i = Ω \cup_{i=1}^k A_i = \Omega ∪ i = 1 k A i = Ω ∑ i = 1 k P ( A i ) = 1 \sum_{i=1}^k P(A_i) = 1 ∑ i = 1 k P ( A i ) = 1
¹ 严格来说,事件空间 F \mathcal{F} F ∅ ∈ F \emptyset \in \mathcal{F} ∅ ∈ F A ∈ F A \in \mathcal{F} A ∈ F Ω ∖ A ∈ F \Omega \setminus A \in \mathcal{F} Ω ∖ A ∈ F A 1 , A 2 , … ∈ F A_1, A_2, \ldots \in \mathcal{F} A 1 , A 2 , … ∈ F ∪ i A i ∈ F \cup_i A_i \in \mathcal{F} ∪ i A i ∈ F
1.1 条件概率与独立性#
设 B 为一个概率不为零的事件。事件 A 在事件 B 已发生的条件下的条件概率 (Conditional Probability) 定义为:P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A|B) = \frac{P(A \cap B)}{P(B)} P ( A ∣ B ) = P ( B ) P ( A ∩ B ) P ( A ∣ B ) P(A|B) P ( A ∣ B )
两个事件 A 和 B 被称为独立的 (Independent) ,当且仅当 P ( A ∩ B ) = P ( A ) P ( B ) P(A \cap B) = P(A)P(B) P ( A ∩ B ) = P ( A ) P ( B ) P ( A ∣ B ) = P ( A ) P(A|B) = P(A) P ( A ∣ B ) = P ( A )
2. 随机变量#
考虑一个投掷10次硬币的实验,并关心出现正面的总次数。在这个场景下,样本空间 Ω \Omega Ω ω 0 = ( H , H , T , … , T ) \omega_0 = (H, H, T, \ldots, T) ω 0 = ( H , H , T , … , T ) 随机变量 (Random Variables) 。
更正式地,一个随机变量 X X X Ω \Omega Ω R \mathbb{R} R X : Ω → R X : \Omega \rightarrow \mathbb{R} X : Ω → R X X X x x x
离散随机变量 : 如果一个随机变量只能取有限个或可数无限个值,则称其为离散随机变量 (Discrete Random Variable) 。例如,在投掷10次硬币的实验中,代表正面次数的随机变量 X X X V a l ( X ) = { 0 , 1 , … , 10 } Val(X) = \{0, 1, \dots, 10\} Va l ( X ) = { 0 , 1 , … , 10 } P ( X = k ) : = P ( { ω ∈ Ω : X ( ω ) = k } ) P(X = k) := P(\{\omega \in \Omega : X(\omega) = k\}) P ( X = k ) := P ({ ω ∈ Ω : X ( ω ) = k })
连续随机变量 : 如果一个随机变量可以取某一区间内的任意实数值,则称其为连续随机变量 (Continuous Random Variable) 。例如,一个表示放射性粒子衰变所需时间的随机变量 X X X P ( a ≤ X ≤ b ) : = P ( { ω ∈ Ω : a ≤ X ( ω ) ≤ b } ) P(a \le X \le b) := P(\{\omega \in \Omega : a \le X(\omega) \le b\}) P ( a ≤ X ≤ b ) := P ({ ω ∈ Ω : a ≤ X ( ω ) ≤ b })
² 从测度论的角度,一个函数要成为随机变量,必须是“博雷尔可测的”(Borel-measurable)。这一限制确保了诸如 { ω : X ( ω ) ≤ x } \{\omega : X(\omega) \le x\} { ω : X ( ω ) ≤ x } F \mathcal{F} F
2.1 累积分布函数 (CDF)#
为了描述随机变量的概率特性,我们引入了几个关键函数(CDF、PDF 和 PMF)。在本节和接下来的两节中,我们将依次描述这些类型的函数。
累积分布函数 (Cumulative Distribution Function, CDF) 是其中最基本的一个,它定义为:F X ( x ) ≜ P ( X ≤ x ) F_X(x) \triangleq P(X \le x) F X ( x ) ≜ P ( X ≤ x ) F X ( x ) F_X(x) F X ( x ) X X X 不大于 x x x 的概率。通过 CDF,我们可以计算出 X X X
CDF 的性质 :
0 ≤ F X ( x ) ≤ 1 0 \le F_X(x) \le 1 0 ≤ F X ( x ) ≤ 1 lim x → − ∞ F X ( x ) = 0 \lim_{x \to -\infty} F_X(x) = 0 lim x → − ∞ F X ( x ) = 0 lim x → ∞ F X ( x ) = 1 \lim_{x \to \infty} F_X(x) = 1 lim x → ∞ F X ( x ) = 1 F X ( x ) F_X(x) F X ( x ) x ≤ y x \le y x ≤ y F X ( x ) ≤ F X ( y ) F_X(x) \le F_X(y) F X ( x ) ≤ F X ( y )
2.2 概率质量函数 (PMF)#
对于离散随机变量,我们可以用一种更直观的方式来描述其分布,即概率质量函数 (Probability Mass Function, PMF) 。PMF 直接给出了随机变量取每一个可能值的概率:p X ( x ) ≜ P ( X = x ) p_X(x) \triangleq P(X = x) p X ( x ) ≜ P ( X = x ) PMF 的性质 :
0 ≤ p X ( x ) ≤ 1 0 \le p_X(x) \le 1 0 ≤ p X ( x ) ≤ 1 ∑ x ∈ V a l ( X ) p X ( x ) = 1 \sum_{x \in Val(X)} p_X(x) = 1 ∑ x ∈ Va l ( X ) p X ( x ) = 1 ∑ x ∈ A p X ( x ) = P ( X ∈ A ) \sum_{x \in A} p_X(x) = P(X \in A) ∑ x ∈ A p X ( x ) = P ( X ∈ A )
另外,我们使用符号 V a l ( X ) Val(X) Va l ( X ) X ( ω ) X(\omega) X ( ω ) V a l ( X ) = { 0 , 1 , 2 , … , 10 } Val(X) = \{0, 1, 2, \ldots, 10\} Va l ( X ) = { 0 , 1 , 2 , … , 10 }
2.3 概率密度函数 (PDF)#
对于连续随机变量,由于其在任何单点取值的概率为零,PMF 的概念不再适用。取而代之,我们使用概率密度函数 (Probability Density Function, PDF) 。如果一个连续随机变量的 CDF 函数 F X ( x ) F_X(x) F X ( x ) 处处可微 ,那么其 PDF 定义为其 CDF 的导数:f X ( x ) ≜ d F X ( x ) d x f_X(x) \triangleq \frac{dF_X(x)}{dx} f X ( x ) ≜ d x d F X ( x ) Δ x \Delta x Δ x P ( x ≤ X ≤ x + Δ x ) ≈ f X ( x ) Δ x P(x \le X \le x + \Delta x) \approx f_X(x) \Delta x P ( x ≤ X ≤ x + Δ x ) ≈ f X ( x ) Δ x f X ( x ) f_X(x) f X ( x ) 不代表 概率,它描述的是概率在点 x x x f X ( x ) f_X(x) f X ( x )
PDF 的性质 :
f X ( x ) ≥ 0 f_X(x) \ge 0 f X ( x ) ≥ 0 ∫ − ∞ ∞ f X ( x ) d x = 1 \int_{-\infty}^{\infty} f_X(x) dx = 1 ∫ − ∞ ∞ f X ( x ) d x = 1 ∫ A f X ( x ) d x = P ( X ∈ A ) \int_{A} f_X(x) dx = P(X \in A) ∫ A f X ( x ) d x = P ( X ∈ A )
2.4 期望#
随机变量的期望 (Expectation) 是其所有可能取值的加权平均,权重为其对应的概率(或概率密度)。对于任意函数 g ( X ) g(X) g ( X ) E [ g ( X ) ] E[g(X)] E [ g ( X )]
离散情况 :E [ g ( X ) ] ≜ ∑ x ∈ V a l ( X ) g ( x ) p X ( x ) E[g(X)] \triangleq \sum_{x \in Val(X)} g(x) p_X(x) E [ g ( X )] ≜ ∑ x ∈ Va l ( X ) g ( x ) p X ( x ) 连续情况 :E [ g ( X ) ] ≜ ∫ − ∞ ∞ g ( x ) f X ( x ) d x E[g(X)] \triangleq \int_{-\infty}^{\infty} g(x) f_X(x) dx E [ g ( X )] ≜ ∫ − ∞ ∞ g ( x ) f X ( x ) d x g ( x ) = x g(x) = x g ( x ) = x X X X E [ X ] E[X] E [ X ] 均值 (Mean) 。
性质 :
对于常数 a a a E [ a ] = a E[a] = a E [ a ] = a
对于常数 a a a E [ a f ( X ) ] = a E [ f ( X ) ] E[a f(X)] = a E[f(X)] E [ a f ( X )] = a E [ f ( X )]
E [ f ( X ) + g ( X ) ] = E [ f ( X ) ] + E [ g ( X ) ] E[f(X) + g(X)] = E[f(X)] + E[g(X)] E [ f ( X ) + g ( X )] = E [ f ( X )] + E [ g ( X )] 对于离散变量,E [ 1 { X = k } ] = P ( X = k ) E[1\{X=k\}] = P(X=k) E [ 1 { X = k }] = P ( X = k ) 1 { ⋅ } 1\{\cdot\} 1 { ⋅ }
2.5 方差#
方差 (Variance) 用于度量随机变量的取值在其均值附近的分散程度。其定义为:V a r [ X ] ≜ E [ ( X − E [ X ] ) 2 ] Var[X] \triangleq E[(X - E[X])^2] Va r [ X ] ≜ E [( X − E [ X ] ) 2 ] V a r [ X ] = E [ X 2 − 2 X E [ X ] + ( E [ X ] ) 2 ] = E [ X 2 ] − E [ X ] 2 Var[X] = E[X^2 - 2X E[X] + (E[X])^2] = E[X^2] - E[X]^2 Va r [ X ] = E [ X 2 − 2 XE [ X ] + ( E [ X ] ) 2 ] = E [ X 2 ] − E [ X ] 2
性质 :
对于常数 a a a V a r [ a ] = 0 Var[a] = 0 Va r [ a ] = 0
对于常数 a a a V a r [ a f ( X ) ] = a 2 V a r [ f ( X ) ] Var[a f(X)] = a^2 Var[f(X)] Va r [ a f ( X )] = a 2 Va r [ f ( X )]
示例 :计算在 [ 0 , 1 ] [0, 1] [ 0 , 1 ] X X X f X ( x ) = 1 , ∀ x ∈ [ 0 , 1 ] f_X(x) = 1, \forall x \in [0, 1] f X ( x ) = 1 , ∀ x ∈ [ 0 , 1 ]
均值 : E [ X ] = ∫ 0 1 x ⋅ 1 d x = 1 2 E[X] = \int_0^1 x \cdot 1 dx = \frac{1}{2} E [ X ] = ∫ 0 1 x ⋅ 1 d x = 2 1 X 2 X^2 X 2 E [ X 2 ] = ∫ 0 1 x 2 ⋅ 1 d x = 1 3 E[X^2] = \int_0^1 x^2 \cdot 1 dx = \frac{1}{3} E [ X 2 ] = ∫ 0 1 x 2 ⋅ 1 d x = 3 1 方差 : V a r [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = 1 3 − ( 1 2 ) 2 = 1 12 Var[X] = E[X^2] - (E[X])^2 = \frac{1}{3} - (\frac{1}{2})^2 = \frac{1}{12} Va r [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = 3 1 − ( 2 1 ) 2 = 12 1
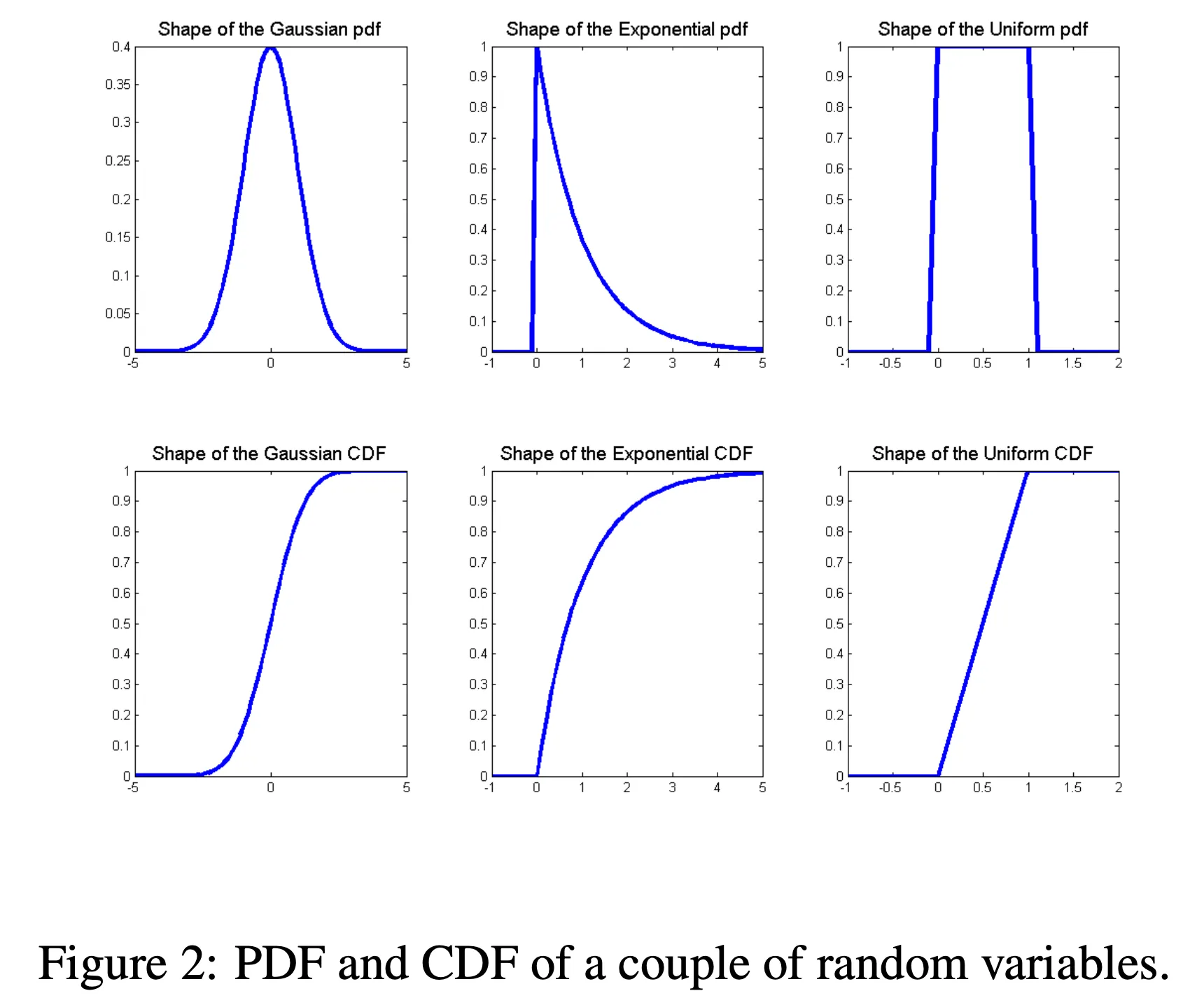
2.6 常见随机变量分布#
对于离散随机变量
X ∼ Bernoulli ( p ) X \sim \text{Bernoulli}(p) X ∼ Bernoulli ( p ) 0 ≤ p ≤ 1 0 \le p \le 1 0 ≤ p ≤ 1 p ( x ) = { p if x = 1 1 − p if x = 0 p(x) = \begin{cases} p & \text{if } x=1 \\ 1-p & \text{if } x=0 \end{cases} p ( x ) = { p 1 − p if x = 1 if x = 0 X ∼ Binomial ( n , p ) X \sim \text{Binomial}(n, p) X ∼ Binomial ( n , p ) 0 ≤ p ≤ 1 0 \le p \le 1 0 ≤ p ≤ 1 p ( x ) = ( n x ) p x ( 1 − p ) n − x p(x) = \binom{n}{x} p^x (1-p)^{n-x} p ( x ) = ( x n ) p x ( 1 − p ) n − x X ∼ Geometric ( p ) X \sim \text{Geometric}(p) X ∼ Geometric ( p ) p > 0 p > 0 p > 0 p ( x ) = p ( 1 − p ) x − 1 p(x) = p(1-p)^{x-1} p ( x ) = p ( 1 − p ) x − 1 X ∼ Poisson ( λ ) X \sim \text{Poisson}(\lambda) X ∼ Poisson ( λ ) λ > 0 \lambda > 0 λ > 0 p ( x ) = e − λ λ x x ! p(x) = e^{-\lambda} \frac{\lambda^x}{x!} p ( x ) = e − λ x ! λ x
对于连续随机变量
X ∼ Uniform ( a , b ) X \sim \text{Uniform}(a, b) X ∼ Uniform ( a , b ) a < b a < b a < b f ( x ) = { 1 b − a if a ≤ x ≤ b 0 otherwise f(x) = \begin{cases} \frac{1}{b-a} & \text{if } a \le x \le b \\ 0 & \text{otherwise} \end{cases} f ( x ) = { b − a 1 0 if a ≤ x ≤ b otherwise X ∼ Exponential ( λ ) X \sim \text{Exponential}(\lambda) X ∼ Exponential ( λ ) λ > 0 \lambda > 0 λ > 0 f ( x ) = { λ e − λ x if x ≥ 0 0 otherwise f(x) = \begin{cases} \lambda e^{-\lambda x} & \text{if } x \ge 0 \\ 0 & \text{otherwise} \end{cases} f ( x ) = { λ e − λ x 0 if x ≥ 0 otherwise X ∼ Normal ( μ , σ 2 ) X \sim \text{Normal}(\mu, \sigma^2) X ∼ Normal ( μ , σ 2 ) f ( x ) = 1 2 π σ exp ( − 1 2 σ 2 ( x − μ ) 2 ) f(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{1}{2\sigma^2}(x-\mu)^2\right) f ( x ) = 2 π σ 1 exp ( − 2 σ 2 1 ( x − μ ) 2 )
下表总结了这些分布的关键性质:
分布 PDF 或 PMF 均值 (Mean) 方差 (Variance) Bernoulli(p) p x ( 1 − p ) 1 − x p^x(1-p)^{1-x} p x ( 1 − p ) 1 − x x ∈ { 0 , 1 } x \in \{0,1\} x ∈ { 0 , 1 } p p p p ( 1 − p ) p(1-p) p ( 1 − p ) Binomial(n,p) ( n k ) p k ( 1 − p ) n − k \binom{n}{k}p^k(1-p)^{n-k} ( k n ) p k ( 1 − p ) n − k n p np n p n p ( 1 − p ) np(1-p) n p ( 1 − p ) Geometric(p) p ( 1 − p ) k − 1 p(1-p)^{k-1} p ( 1 − p ) k − 1 k = 1 , 2 , … k=1,2,\ldots k = 1 , 2 , … 1 / p 1/p 1/ p ( 1 − p ) / p 2 (1-p)/p^2 ( 1 − p ) / p 2 Poisson(λ \lambda λ e − λ λ x / x ! e^{-\lambda}\lambda^x/x! e − λ λ x / x ! λ \lambda λ λ \lambda λ Uniform(a, b) 1 / ( b − a ) 1/(b-a) 1/ ( b − a ) x ∈ [ a , b ] x \in [a,b] x ∈ [ a , b ] ( a + b ) / 2 (a+b)/2 ( a + b ) /2 ( b − a ) 2 / 12 (b-a)^2/12 ( b − a ) 2 /12 Gaussian(μ , σ 2 \mu, \sigma^2 μ , σ 2 1 σ 2 π exp ( − ( x − μ ) 2 2 σ 2 ) \frac{1}{\sigma\sqrt{2\pi}}\exp(-\frac{(x-\mu)^2}{2\sigma^2}) σ 2 π 1 exp ( − 2 σ 2 ( x − μ ) 2 ) μ \mu μ σ 2 \sigma^2 σ 2 Exponential(λ \lambda λ λ e − λ x \lambda e^{-\lambda x} λ e − λ x x ≥ 0 x \ge 0 x ≥ 0 1 / λ 1/\lambda 1/ λ 1 / λ 2 1/\lambda^2 1/ λ 2
3. 两个随机变量#
到目前为止,我们只考虑了单个随机变量。然而,在许多情况下,我们可能对随机实验中的多个量感兴趣。例如,在抛掷十次硬币的实验中,我们可能同时关心正面出现的总次数 X X X Y Y Y
3.1 联合分布与边缘分布#
假设我们有两个随机变量 X 和 Y。处理这两个随机变量的一种方法是分别考虑它们中的每一个。如果我们这样做,我们只需要 F X ( x ) F_X(x) F X ( x ) F Y ( y ) F_Y(y) F Y ( y ) 联合分布 (Joint Distribution) 。
联合累积分布函数 (Joint CDF) 定义为:F X Y ( x , y ) = P ( X ≤ x , Y ≤ y ) F_{XY}(x, y) = P(X \le x, Y \le y) F X Y ( x , y ) = P ( X ≤ x , Y ≤ y )
我们可以从联合分布中恢复出单个变量的分布,这被称为边缘分布 (Marginal Distribution) 。F X ( x ) = lim y → ∞ F X Y ( x , y ) F_X(x) = \lim_{y \to \infty} F_{XY}(x, y) F X ( x ) = lim y → ∞ F X Y ( x , y ) F Y ( y ) = lim x → ∞ F X Y ( x , y ) F_Y(y) = \lim_{x \to \infty} F_{XY}(x, y) F Y ( y ) = lim x → ∞ F X Y ( x , y )
对于离散变量,联合 PMF 为 p X Y ( x , y ) = P ( X = x , Y = y ) p_{XY}(x, y) = P(X=x, Y=y) p X Y ( x , y ) = P ( X = x , Y = y ) 边缘 PMF 则通过对另一个变量的所有可能值求和得到:p X ( x ) = ∑ y p X Y ( x , y ) p_X(x) = \sum_y p_{XY}(x, y) p X ( x ) = ∑ y p X Y ( x , y )
对于连续变量,联合 PDF 为 f X Y ( x , y ) f_{XY}(x, y) f X Y ( x , y ) 边缘 PDF 通过对另一个变量在整个实数域上积分得到:f X ( x ) = ∫ − ∞ ∞ f X Y ( x , y ) d y f_X(x) = \int_{-\infty}^{\infty} f_{XY}(x, y) dy f X ( x ) = ∫ − ∞ ∞ f X Y ( x , y ) d y 边缘化 (Marginalization) 。
3.2 条件分布#
条件分布 (Conditional Distribution) 旨在回答:当已知一个随机变量 X X X x x x Y Y Y
离散情况 : 条件 PMF 定义为:p Y ∣ X ( y ∣ x ) = p X Y ( x , y ) p X ( x ) , 前提 p X ( x ) > 0 p_{Y|X}(y|x) = \frac{p_{XY}(x, y)}{p_X(x)}, \quad \text{前提 } p_X(x) > 0 p Y ∣ X ( y ∣ x ) = p X ( x ) p X Y ( x , y ) , 前提 p X ( x ) > 0 连续情况 : 条件 PDF 定义为:f Y ∣ X ( y ∣ x ) = f X Y ( x , y ) f X ( x ) , 前提 f X ( x ) > 0 f_{Y|X}(y|x) = \frac{f_{XY}(x, y)}{f_X(x)}, \quad \text{前提 } f_X(x) > 0 f Y ∣ X ( y ∣ x ) = f X ( x ) f X Y ( x , y ) , 前提 f X ( x ) > 0
3.3 联合和边缘概率密度函数#
设 X 和 Y 是两个具有联合分布函数 F X Y F_{XY} F X Y F X Y ( x , y ) F_{XY}(x, y) F X Y ( x , y ) 联合概率密度函数 :f X Y ( x , y ) = ∂ 2 F X Y ( x , y ) ∂ x ∂ y f_{XY}(x, y) = \frac{\partial^2 F_{XY}(x, y)}{\partial x \partial y} f X Y ( x , y ) = ∂ x ∂ y ∂ 2 F X Y ( x , y ) f X Y ( x , y ) ≠ P ( X = x , Y = y ) f_{XY}(x, y) \ne P(X=x, Y=y) f X Y ( x , y ) = P ( X = x , Y = y ) ∫ A ∫ f X Y ( x , y ) d x d y = P ( ( X , Y ) ∈ A ) \int_{A} \int f_{XY}(x, y) dx dy = P((X, Y) \in A) ∫ A ∫ f X Y ( x , y ) d x d y = P (( X , Y ) ∈ A ) f X ( x ) = ∫ − ∞ ∞ f X Y ( x , y ) d y f_X(x) = \int_{-\infty}^{\infty} f_{XY}(x, y) dy f X ( x ) = ∫ − ∞ ∞ f X Y ( x , y ) d y 边缘概率密度函数 (或边缘密度),f Y ( y ) f_Y(y) f Y ( y )
3.4 条件分布#
条件分布试图回答这样一个问题:当我们知道 X 必须取某个特定值 x x x
在离散情况下,给定 Y 的 X 的条件概率质量函数 很简单:p Y ∣ X ( y ∣ x ) = p X Y ( x , y ) p X ( x ) p_{Y|X}(y|x) = \frac{p_{XY}(x, y)}{p_X(x)} p Y ∣ X ( y ∣ x ) = p X ( x ) p X Y ( x , y ) p X ( x ) ≠ 0 p_X(x) \ne 0 p X ( x ) = 0
在连续情况下,情况在技术上要复杂一些,因为连续随机变量 X 取特定值 x x x X = x X=x X = x 条件概率密度 为:f Y ∣ X ( y ∣ x ) = f X Y ( x , y ) f X ( x ) f_{Y|X}(y|x) = \frac{f_{XY}(x, y)}{f_X(x)} f Y ∣ X ( y ∣ x ) = f X ( x ) f X Y ( x , y ) f X ( x ) ≠ 0 f_X(x) \ne 0 f X ( x ) = 0
3.5 贝叶斯法则#
在试图推导一个变量给定另一个变量的条件概率表达式时,一个经常出现的有用公式是贝叶斯法则 。P Y ∣ X ( y ∣ x ) = P X Y ( x , y ) P X ( x ) = P X ∣ Y ( x ∣ y ) P Y ( y ) ∑ y ′ ∈ V a l ( Y ) P X ∣ Y ( x ∣ y ′ ) P Y ( y ′ ) P_{Y|X}(y|x) = \frac{P_{XY}(x,y)}{P_X(x)} = \frac{P_{X|Y}(x|y)P_Y(y)}{\sum_{y' \in Val(Y)} P_{X|Y}(x|y')P_Y(y')} P Y ∣ X ( y ∣ x ) = P X ( x ) P X Y ( x , y ) = ∑ y ′ ∈ Va l ( Y ) P X ∣ Y ( x ∣ y ′ ) P Y ( y ′ ) P X ∣ Y ( x ∣ y ) P Y ( y ) f Y ∣ X ( y ∣ x ) = f X Y ( x , y ) f X ( x ) = f X ∣ Y ( x ∣ y ) f Y ( y ) ∫ − ∞ ∞ f X ∣ Y ( x ∣ y ′ ) f Y ( y ′ ) d y ′ f_{Y|X}(y|x) = \frac{f_{XY}(x,y)}{f_X(x)} = \frac{f_{X|Y}(x|y)f_Y(y)}{\int_{-\infty}^{\infty} f_{X|Y}(x|y')f_Y(y')dy'} f Y ∣ X ( y ∣ x ) = f X ( x ) f X Y ( x , y ) = ∫ − ∞ ∞ f X ∣ Y ( x ∣ y ′ ) f Y ( y ′ ) d y ′ f X ∣ Y ( x ∣ y ) f Y ( y )
3.6 独立性#
两个随机变量 X 和 Y 是独立 的,如果对于所有 x 和 y 的值,F X Y ( x , y ) = F X ( x ) F Y ( y ) F_{XY}(x, y) = F_X(x)F_Y(y) F X Y ( x , y ) = F X ( x ) F Y ( y )
对于离散随机变量,p X Y ( x , y ) = p X ( x ) p Y ( y ) p_{XY}(x, y) = p_X(x)p_Y(y) p X Y ( x , y ) = p X ( x ) p Y ( y ) x ∈ V a l ( X ) , y ∈ V a l ( Y ) x \in Val(X), y \in Val(Y) x ∈ Va l ( X ) , y ∈ Va l ( Y )
对于离散随机变量,只要 p X ( x ) ≠ 0 p_X(x) \ne 0 p X ( x ) = 0 p Y ∣ X ( y ∣ x ) = p Y ( y ) p_{Y|X}(y|x) = p_Y(y) p Y ∣ X ( y ∣ x ) = p Y ( y ) y ∈ V a l ( Y ) y \in Val(Y) y ∈ Va l ( Y )
对于连续随机变量,f X Y ( x , y ) = f X ( x ) f Y ( y ) f_{XY}(x, y) = f_X(x)f_Y(y) f X Y ( x , y ) = f X ( x ) f Y ( y ) x , y ∈ R x, y \in \mathbb{R} x , y ∈ R
对于连续随机变量,只要 f X ( x ) ≠ 0 f_X(x) \ne 0 f X ( x ) = 0 f Y ∣ X ( y ∣ x ) = f Y ( y ) f_{Y|X}(y|x) = f_Y(y) f Y ∣ X ( y ∣ x ) = f Y ( y ) y ∈ R y \in \mathbb{R} y ∈ R
非正式地说,两个随机变量 X 和 Y 是独立的,如果“知道”一个变量的值永远不会对另一个变量的条件概率分布产生任何影响。
3.7 期望和协方差#
假设我们有两个随机变量 X, Y 和一个函数 g : R 2 → R g : \mathbb{R}^2 \rightarrow \mathbb{R} g : R 2 → R E [ g ( X , Y ) ] ≜ ∑ x ∈ V a l ( X ) ∑ y ∈ V a l ( Y ) g ( x , y ) p X Y ( x , y ) E[g(X, Y)] \triangleq \sum_{x \in Val(X)} \sum_{y \in Val(Y)} g(x, y) p_{XY}(x, y) E [ g ( X , Y )] ≜ ∑ x ∈ Va l ( X ) ∑ y ∈ Va l ( Y ) g ( x , y ) p X Y ( x , y ) E [ g ( X , Y ) ] ≜ ∫ − ∞ ∞ ∫ − ∞ ∞ g ( x , y ) f X Y ( x , y ) d x d y E[g(X, Y)] \triangleq \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} g(x, y) f_{XY}(x, y) dx dy E [ g ( X , Y )] ≜ ∫ − ∞ ∞ ∫ − ∞ ∞ g ( x , y ) f X Y ( x , y ) d x d y 协方差 定义为:C o v [ X , Y ] ≜ E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] Cov[X, Y] \triangleq E[(X - E[X])(Y - E[Y])] C o v [ X , Y ] ≜ E [( X − E [ X ]) ( Y − E [ Y ])] C o v [ X , Y ] = E [ X Y − X E [ Y ] − Y E [ X ] + E [ X ] E [ Y ] ] Cov[X, Y] = E[XY - X E[Y] - Y E[X] + E[X] E[Y]] C o v [ X , Y ] = E [ X Y − XE [ Y ] − Y E [ X ] + E [ X ] E [ Y ]] = E [ X Y ] − E [ X ] E [ Y ] − E [ Y ] E [ X ] + E [ X ] E [ Y ] = E[XY] - E[X]E[Y] - E[Y]E[X] + E[X]E[Y] = E [ X Y ] − E [ X ] E [ Y ] − E [ Y ] E [ X ] + E [ X ] E [ Y ] = E [ X Y ] − E [ X ] E [ Y ] = E[XY] - E[X]E[Y] = E [ X Y ] − E [ X ] E [ Y ]
当 C o v [ X , Y ] = 0 Cov[X, Y] = 0 C o v [ X , Y ] = 0 不相关 的。
如果 C o v ( X , Y ) > 0 Cov(X, Y) > 0 C o v ( X , Y ) > 0
如果 C o v ( X , Y ) < 0 Cov(X, Y) < 0 C o v ( X , Y ) < 0
性质 :
E [ f ( X , Y ) + g ( X , Y ) ] = E [ f ( X , Y ) ] + E [ g ( X , Y ) ] E[f(X, Y) + g(X, Y)] = E[f(X, Y)] + E[g(X, Y)] E [ f ( X , Y ) + g ( X , Y )] = E [ f ( X , Y )] + E [ g ( X , Y )] V a r [ X + Y ] = V a r [ X ] + V a r [ Y ] + 2 C o v [ X , Y ] Var[X + Y] = Var[X] + Var[Y] + 2Cov[X, Y] Va r [ X + Y ] = Va r [ X ] + Va r [ Y ] + 2 C o v [ X , Y ] 如果 X 和 Y 独立,则 C o v [ X , Y ] = 0 Cov[X, Y] = 0 C o v [ X , Y ] = 0
反之不成立 !不相关不一定独立。例如,设 且 Y = X 2 Y=X^2 Y = X 2 C o v ( X , Y ) = 0 Cov(X,Y)=0 C o v ( X , Y ) = 0 如果 X 和 Y 独立,则 E [ f ( X ) g ( Y ) ] = E [ f ( X ) ] E [ g ( Y ) ] E[f(X)g(Y)] = E[f(X)]E[g(Y)] E [ f ( X ) g ( Y )] = E [ f ( X )] E [ g ( Y )]
4. 多个随机变量#
以上关于两个随机变量的概念可以自然地推广到 n n n X 1 , … , X n X_1, \ldots, X_n X 1 , … , X n
4.1 基本性质#
4.1 基本性质#
我们可以定义 联合分布函数 (joint distribution function)F X 1 , X 2 , … , X n F_{X_1,X_2,\ldots,X_n} F X 1 , X 2 , … , X n 联合概率密度函数 (joint probability density function)f X 1 , X 2 , … , X n f_{X_1,X_2,\ldots,X_n} f X 1 , X 2 , … , X n 边缘概率密度函数 (marginal probability density function)f X 1 f_{X_1} f X 1 条件概率密度函数 (conditional probability density function)f X 1 ∣ X 2 , … , X n f_{X_1|X_2,\ldots,X_n} f X 1 ∣ X 2 , … , X n
F X 1 , … , X n ( x 1 , x 2 , … , x n ) = P ( X 1 ≤ x 1 , X 2 ≤ x 2 , … , X n ≤ x n ) F_{X_1,\ldots,X_n}(x_1,x_2,\ldots,x_n) = P(X_1 \le x_1, X_2 \le x_2, \ldots, X_n \le x_n) F X 1 , … , X n ( x 1 , x 2 , … , x n ) = P ( X 1 ≤ x 1 , X 2 ≤ x 2 , … , X n ≤ x n ) f X 1 , … , X n ( x 1 , x 2 , … , x n ) = ∂ n F X 1 , … , X n ( x 1 , x 2 , … , x n ) ∂ x 1 ⋯ ∂ x n f_{X_1,\ldots,X_n}(x_1,x_2,\ldots,x_n) =
\frac{\partial^n F_{X_1,\ldots,X_n}(x_1,x_2,\ldots,x_n)}{\partial x_1 \cdots \partial x_n} f X 1 , … , X n ( x 1 , x 2 , … , x n ) = ∂ x 1 ⋯ ∂ x n ∂ n F X 1 , … , X n ( x 1 , x 2 , … , x n ) f X 1 ( x 1 ) = ∫ − ∞ ∞ ⋯ ∫ − ∞ ∞ f X 1 , … , X n ( x 1 , x 2 , … , x n ) d x 2 ⋯ d x n f_{X_1}(x_1) = \int_{-\infty}^{\infty} \cdots \int_{-\infty}^{\infty}
f_{X_1,\ldots,X_n}(x_1,x_2,\ldots,x_n) dx_2 \cdots dx_n f X 1 ( x 1 ) = ∫ − ∞ ∞ ⋯ ∫ − ∞ ∞ f X 1 , … , X n ( x 1 , x 2 , … , x n ) d x 2 ⋯ d x n f X 1 ∣ X 2 , … , X n ( x 1 ∣ x 2 , … , x n ) = f X 1 , … , X n ( x 1 , x 2 , … , x n ) f X 2 , … , X n ( x 2 , … , x n ) f_{X_1|X_2,\ldots,X_n}(x_1|x_2,\ldots,x_n) =
\frac{f_{X_1,\ldots,X_n}(x_1,x_2,\ldots,x_n)}{f_{X_2,\ldots,X_n}(x_2,\ldots,x_n)} f X 1 ∣ X 2 , … , X n ( x 1 ∣ x 2 , … , x n ) = f X 2 , … , X n ( x 2 , … , x n ) f X 1 , … , X n ( x 1 , x 2 , … , x n ) 为了计算一个事件 A ⊆ R n A \subseteq \mathbb{R}^n A ⊆ R n
P ( ( x 1 , x 2 , … , x n ) ∈ A ) = ∫ ( x 1 , … , x n ) ∈ A f X 1 , … , X n ( x 1 , x 2 , … , x n ) d x 1 d x 2 ⋯ d x n (4) P\big((x_1,x_2,\ldots,x_n) \in A\big) = \int_{(x_1,\ldots,x_n)\in A}
f_{X_1,\ldots,X_n}(x_1,x_2,\ldots,x_n)\, dx_1 dx_2 \cdots dx_n \tag{4} P ( ( x 1 , x 2 , … , x n ) ∈ A ) = ∫ ( x 1 , … , x n ) ∈ A f X 1 , … , X n ( x 1 , x 2 , … , x n ) d x 1 d x 2 ⋯ d x n ( 4 ) 链式法则(Chain rule):
f ( x 1 , x 2 , … , x n ) = f ( x n ∣ x 1 , x 2 , … , x n − 1 ) f ( x 1 , x 2 , … , x n − 1 ) f(x_1,x_2,\ldots,x_n)
= f(x_n|x_1,x_2,\ldots,x_{n-1}) f(x_1,x_2,\ldots,x_{n-1}) f ( x 1 , x 2 , … , x n ) = f ( x n ∣ x 1 , x 2 , … , x n − 1 ) f ( x 1 , x 2 , … , x n − 1 ) = f ( x n ∣ x 1 , x 2 , … , x n − 1 ) f ( x n − 1 ∣ x 1 , x 2 , … , x n − 2 ) f ( x 1 , x 2 , … , x n − 2 ) = f(x_n|x_1,x_2,\ldots,x_{n-1}) f(x_{n-1}|x_1,x_2,\ldots,x_{n-2}) f(x_1,x_2,\ldots,x_{n-2}) = f ( x n ∣ x 1 , x 2 , … , x n − 1 ) f ( x n − 1 ∣ x 1 , x 2 , … , x n − 2 ) f ( x 1 , x 2 , … , x n − 2 ) = ⋯ = f ( x 1 ) ∏ i = 2 n f ( x i ∣ x 1 , … , x i − 1 ) = \cdots = f(x_1) \prod_{i=2}^n f(x_i|x_1,\ldots,x_{i-1}) = ⋯ = f ( x 1 ) i = 2 ∏ n f ( x i ∣ x 1 , … , x i − 1 ) 独立性(Independence): A 1 , … , A k A_1, \ldots, A_k A 1 , … , A k A 1 , … , A k A_1, \ldots, A_k A 1 , … , A k 相互独立 (mutually independent),S ⊆ { 1 , 2 , … , k } S \subseteq \{1,2,\ldots,k\} S ⊆ { 1 , 2 , … , k }
P ( ⋂ i ∈ S A i ) = ∏ i ∈ S P ( A i ) 。 P\Big(\bigcap_{i\in S} A_i\Big) = \prod_{i\in S} P(A_i)。 P ( i ∈ S ⋂ A i ) = i ∈ S ∏ P ( A i ) 。 类似地,若随机变量 X 1 , … , X n X_1,\ldots,X_n X 1 , … , X n
f ( x 1 , … , x n ) = f ( x 1 ) f ( x 2 ) ⋯ f ( x n ) 。 f(x_1,\ldots,x_n) = f(x_1) f(x_2) \cdots f(x_n)。 f ( x 1 , … , x n ) = f ( x 1 ) f ( x 2 ) ⋯ f ( x n ) 。 在这里,互相独立的定义只是从两个随机变量推广到了多个随机变量。
在机器学习算法中,独立随机变量常常出现,因为我们假设训练集中的样本是从某个未知的概率分布中独立采样得到的。为了说明独立性的重要性,可以考虑一个“糟糕”的训练集构造方式:( x ( 1 ) , y ( 1 ) ) (x^{(1)}, y^{(1)}) ( x ( 1 ) , y ( 1 ) ) m − 1 m-1 m − 1
P ( ( x ( 1 ) , y ( 1 ) ) , … , ( x ( m ) , y ( m ) ) ) ≠ ∏ i = 1 m P ( x ( i ) , y ( i ) ) 。 P\big((x^{(1)},y^{(1)}), \ldots, (x^{(m)},y^{(m)})\big) \ne \prod_{i=1}^m P(x^{(i)},y^{(i)})。 P ( ( x ( 1 ) , y ( 1 ) ) , … , ( x ( m ) , y ( m ) ) ) = i = 1 ∏ m P ( x ( i ) , y ( i ) ) 。 虽然训练集大小是 m m m 并不独立 !显然,这种构造方式并不是一种合理的机器学习训练方法。但在实际中,样本间的非独立性确实经常发生,这会减少训练集的“有效规模”(effective size)。
4.2 随机向量#
处理多个随机变量时,将它们组织成一个随机向量 (Random Vector) X = [ X 1 , … , X n ] T X = [X_1, \ldots, X_n]^T X = [ X 1 , … , X n ] T
随机向量的期望 :向量函数 g ( X ) g(X) g ( X ) g : R n → R m g : \mathbb{R}^n \rightarrow \mathbb{R}^m g : R n → R m E [ X ] = [ μ 1 , … , μ n ] T E[X] = [\mu_1, \ldots, \mu_n]^T E [ X ] = [ μ 1 , … , μ n ] T
随机向量的协方差矩阵 :对于一个给定的随机向量 X : Ω → R n X : \Omega \rightarrow \mathbb{R}^n X : Ω → R n 协方差矩阵 Σ \Sigma Σ n × n n \times n n × n ( i , j ) (i,j) ( i , j ) C o v ( X i , X j ) Cov(X_i, X_j) C o v ( X i , X j ) 协方差矩阵(Covariance matrix): X : Ω → R n X : \Omega \to \mathbb{R}^n X : Ω → R n Σ \Sigma Σ n × n n \times n n × n
Σ i j = C o v [ X i , X j ] 。 \Sigma_{ij} = \mathrm{Cov}[X_i, X_j]。 Σ ij = Cov [ X i , X j ] 。 由协方差的定义可得:
Σ = [ C o v [ X 1 , X 1 ] ⋯ C o v [ X 1 , X n ] ⋮ ⋱ ⋮ C o v [ X n , X 1 ] ⋯ C o v [ X n , X n ] ] \Sigma =
\begin{bmatrix}
\mathrm{Cov}[X_1, X_1] & \cdots & \mathrm{Cov}[X_1, X_n] \\
\vdots & \ddots & \vdots \\
\mathrm{Cov}[X_n, X_1] & \cdots & \mathrm{Cov}[X_n, X_n]
\end{bmatrix} Σ = Cov [ X 1 , X 1 ] ⋮ Cov [ X n , X 1 ] ⋯ ⋱ ⋯ Cov [ X 1 , X n ] ⋮ Cov [ X n , X n ] = [ E [ X 1 2 ] − E [ X 1 ] E [ X 1 ] ⋯ E [ X 1 X n ] − E [ X 1 ] E [ X n ] ⋮ ⋱ ⋮ E [ X n X 1 ] − E [ X n ] E [ X 1 ] ⋯ E [ X n 2 ] − E [ X n ] E [ X n ] ] =
\begin{bmatrix}
\mathbb{E}[X_1^2] - \mathbb{E}[X_1]\mathbb{E}[X_1] & \cdots & \mathbb{E}[X_1 X_n] - \mathbb{E}[X_1]\mathbb{E}[X_n] \\
\vdots & \ddots & \vdots \\
\mathbb{E}[X_n X_1] - \mathbb{E}[X_n]\mathbb{E}[X_1] & \cdots & \mathbb{E}[X_n^2] - \mathbb{E}[X_n]\mathbb{E}[X_n]
\end{bmatrix} = E [ X 1 2 ] − E [ X 1 ] E [ X 1 ] ⋮ E [ X n X 1 ] − E [ X n ] E [ X 1 ] ⋯ ⋱ ⋯ E [ X 1 X n ] − E [ X 1 ] E [ X n ] ⋮ E [ X n 2 ] − E [ X n ] E [ X n ] = [ E [ X 1 2 ] ⋯ E [ X 1 X n ] ⋮ ⋱ ⋮ E [ X n X 1 ] ⋯ E [ X n 2 ] ] − [ E [ X 1 ] E [ X 1 ] ⋯ E [ X 1 ] E [ X n ] ⋮ ⋱ ⋮ E [ X n ] E [ X 1 ] ⋯ E [ X n ] E [ X n ] ] =
\begin{bmatrix}
\mathbb{E}[X_1^2] & \cdots & \mathbb{E}[X_1 X_n] \\
\vdots & \ddots & \vdots \\
\mathbb{E}[X_n X_1] & \cdots & \mathbb{E}[X_n^2]
\end{bmatrix}
-
\begin{bmatrix}
\mathbb{E}[X_1]\mathbb{E}[X_1] & \cdots & \mathbb{E}[X_1]\mathbb{E}[X_n] \\
\vdots & \ddots & \vdots \\
\mathbb{E}[X_n]\mathbb{E}[X_1] & \cdots & \mathbb{E}[X_n]\mathbb{E}[X_n]
\end{bmatrix} = E [ X 1 2 ] ⋮ E [ X n X 1 ] ⋯ ⋱ ⋯ E [ X 1 X n ] ⋮ E [ X n 2 ] − E [ X 1 ] E [ X 1 ] ⋮ E [ X n ] E [ X 1 ] ⋯ ⋱ ⋯ E [ X 1 ] E [ X n ] ⋮ E [ X n ] E [ X n ] = E [ X X T ] − E [ X ] E [ X ] T = ⋯ = E [ ( X − E [ X ] ) ( X − E [ X ] ) T ] . = \mathbb{E}[X X^T] - \mathbb{E}[X]\mathbb{E}[X]^T
= \cdots
= \mathbb{E}\!\left[(X - \mathbb{E}[X])(X - \mathbb{E}[X])^T\right]. = E [ X X T ] − E [ X ] E [ X ] T = ⋯ = E [ ( X − E [ X ]) ( X − E [ X ] ) T ] . 总结:Σ = E [ X X T ] − E [ X ] E [ X ] T = E [ ( X − E [ X ] ) ( X − E [ X ] ) T ] \Sigma = E[XX^T] - E[X]E[X]^T = E[(X - E[X])(X - E[X])^T] Σ = E [ X X T ] − E [ X ] E [ X ] T = E [( X − E [ X ]) ( X − E [ X ] ) T ]
Σ ⪰ 0 \Sigma \succeq 0 Σ ⪰ 0 Σ \Sigma Σ Σ = Σ T \Sigma = \Sigma^T Σ = Σ T Σ \Sigma Σ 对角线上的元素是各个随机变量的方差。
4.3 多元高斯分布#
在多维随机向量的分布中,多元高斯分布 (Multivariate Gaussian Distribution) 或多元正态分布至关重要。一个随机向量 X ∈ R n X \in \mathbb{R}^n X ∈ R n μ ∈ R n \mu \in \mathbb{R}^n μ ∈ R n Σ ∈ S + + n \Sigma \in \mathbb{S}_{++}^n Σ ∈ S ++ n S + + n \mathbb{S}_{++}^n S ++ n n × n n \times n n × n Σ \Sigma Σ f X 1 , … , X n ( x 1 , … , x n ; μ , Σ ) = 1 ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) f_{X_1, \ldots, X_n}(x_1, \ldots, x_n; \mu, \Sigma) = \frac{1}{(2\pi)^{n/2} |\Sigma|^{1/2}} \exp\left(-\frac{1}{2}(x - \mu)^T \Sigma^{-1} (x - \mu)\right) f X 1 , … , X n ( x 1 , … , x n ; μ , Σ ) = ( 2 π ) n /2 ∣Σ ∣ 1/2 1 exp ( − 2 1 ( x − μ ) T Σ − 1 ( x − μ ) ) X ∼ N ( μ , Σ ) X \sim \mathcal{N}(\mu, \Sigma) X ∼ N ( μ , Σ )
多元高斯分布在机器学习中极其有用,主要原因有二:
中心极限定理 : 许多独立的随机过程的累加效应往往趋近于高斯分布,因此它非常适合为现实世界中的“噪声”建模。分析便利性 : 涉及高斯分布的许多积分(如边缘化、条件化)都有简洁的闭式解,这使得基于它的许多模型在数学上易于处理。
5 其他参考资料#
适合 CS229 水平的概率教材推荐:Sheldon Ross 的 A First Course on Probability 。